Further Analysis
The advantage of pseudolabeling is to generate more labeled
data for the initial small sized training set consisting of lim-
ited labeled data, which can optimize both the performance
of the algorithms and robustness of the classifiers. Therefore,
it is interesting to investigate the performance of
DSC-CASSL
when the training set given a very small sized training set.
Here, we evaluate the performance of
DSC-CASSL
on BOT data
sets (see Table 1) and compare it with that of four methods.
We randomly divided the total data into two parts: 35% for
training and 65% for testing. Then, for the 35% training data,
we randomly selected five samples in each class as the initial
labeled data, and the remaining samples were used as the
unlabeled data. At each iteration in the active learning, 10
samples were selected by manual labeling, and added to the
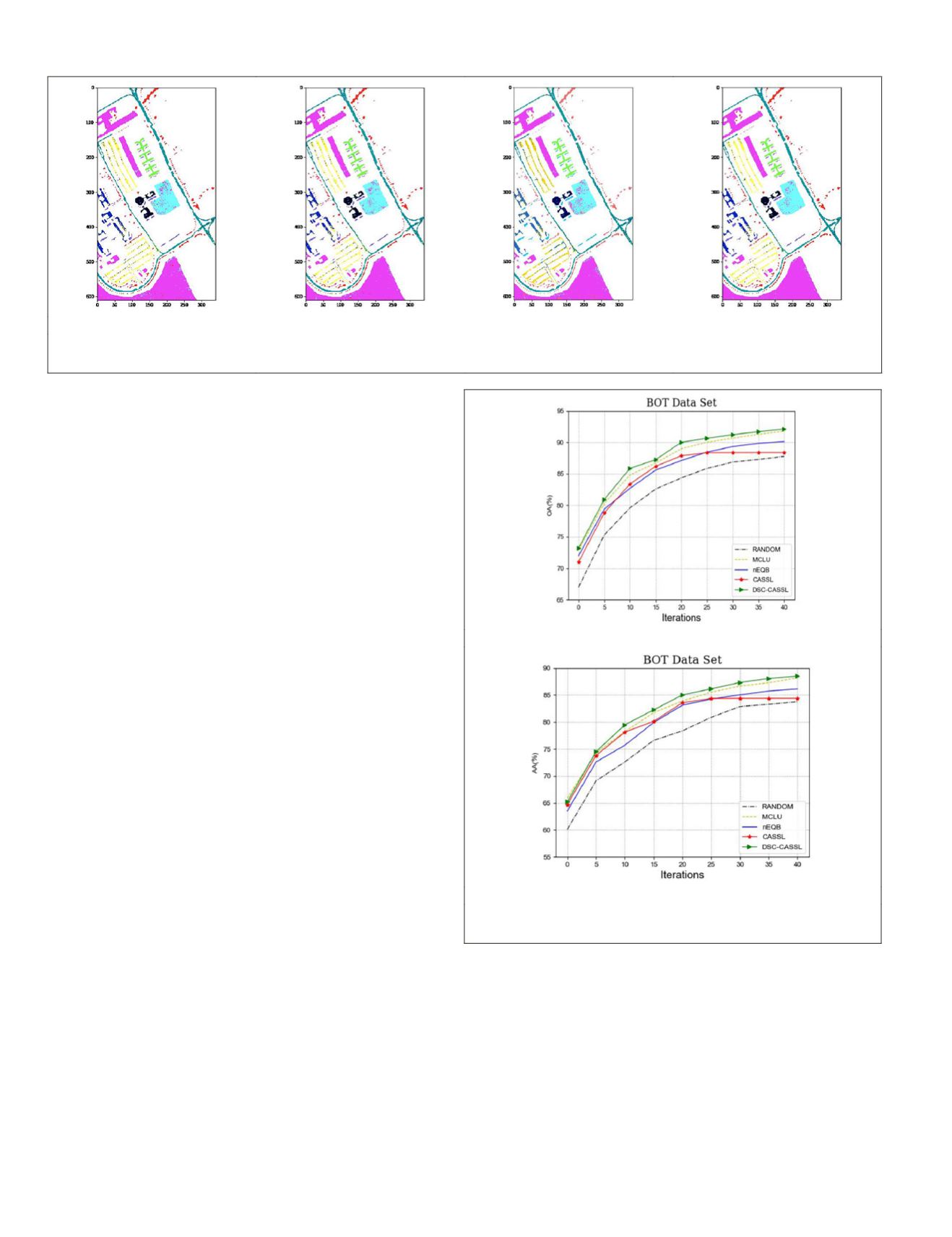
labeled data set. Ten runs were executed on this data set. It
can be observed from Figure 10 the
DSC-CASSL
is superior to
the
CASSL
. We also find that, at the beginning of the iteration,
both
MCLU
and
nEQB
outperform the
CASSL
and
DSC-CASSL
.
The main reason may be that the initial small sized training
set can’t obtain an effective classifier at the very initial stage,
and may assign many wrong pseudolabels. With the itera-
tion of the algorithm, the
DSC-CASSL
begi
comparison methods. This is because th
check algorithm can gradually improve t
accuracy and reduce the performance deterioration.
Conclusions
In this paper, we proposed a novel
DSC-CASSL
framework for
hyperspectral image classification.
DSC-CASSL
combines two
active learning techniques and semisupervised learning in
a collaborative framework, which aims at acquiring more
confidently labeled samples and improving the performance
of the classifiers. Considering the representative information
and discriminative information of the samples,
DSC-CASSL
employs double different strategies to select the two set
of informative samples and label these samples by human
experts. It also utilizes two set of informative samples to train
two verification classifiers, respectively, which aims to ensure
the difference of classifiers and prevents disadvantages that
may be caused by
CASSL
. To empirically assess the effective-
ness of the
DSC-CASSL
algorithm, we compared it with four
methods existing in the literature by using four real hyper-
spectral data sets. By this comparison, we observed that for
all the considered data sets,
DSC-CASSL
consistently achieves
good classification results. Moreover, compared with
CASSL
,
the
DSC-CASSL
implements much less labeling cost and train-
ing time to obtain better performance. In the future work,
we will utilize multiple-verification strategy to enhance the
performance. Hence, an important issue is that how to reduce
computational cost. Utilizing the Spark MLlib framework
(Meng and Bradley 2017) and Apache Mahout technique (Wu
et al.
2015) is a promising idea.
(a)
(b)
Figure 10.
OA
and
AA
results of the different algorithms on the
BOT
data set. (a)
OA
. (b)
AA
.
(a)
(b)
(c)
(d)
Figure 9. Comparison of the classification map of different framework on the Pavia university data set. (a)
MCLU
. (b)
nEQB
. (c)
CASSL
. (d)
DSC-CASSL
.
850
November 2019
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING


