positive, and negative image patches (
I
a
,
I
p
,
I
n
) are generated
through the triple network containing three identical
CNN
.
The purpose of the triple network is to push the descriptors of
the anchor patch and the positive patch (
d
a
,
d
p
) close and pull
the descriptor of the negative pair
d
n
far away from those of
the positive pair in the feature space.
For a conventional
CNN
consisting of a sequence of non-
linear transformations, the parameters
Θ
, including the filter
weights
W
and the biases
b
, determine the deep feature repre-
sentation when an image patch is fed into the network. Given
a
CNN
framework
f
with
L
layers, the output of an image patch
I
is computed as follows:
{
h
l
–1
=
ReLU
(
BN
(
W
l
–1
h
l
–2
+
b
l
–1
)),
l
∈
(2, …,
L
)
f
(
I
;
Θ
) =
ReLU
(
BN
(
W
l
h
l
–1
+
b
l
)),
l
∈
(2, …,
L
)
(7)
where
h
l
,
W
l
, and
b
l
denote, respectively, the
l
th hidden layer,
weights, and biases of the
CNN
; BN and ReLU represent,
respectively, the batch normalizatio
and a type of nonlinear activation (i
(Glorot
et al.
2011). Here,
BN x
Var x
k
k
( )
[ ]
=
ReLU(
x
) = max(0,
x
). During the training process, the param-
eters and are updated through back-propagation using a
gradient descent algorithm via the following equation:
W W
L
W
b b
L
b
l
l
l
l
l
l
← −
∂
∂
← −
∂
∂
η
η
(8)
where
L
is the loss and
η
is the learning rate.
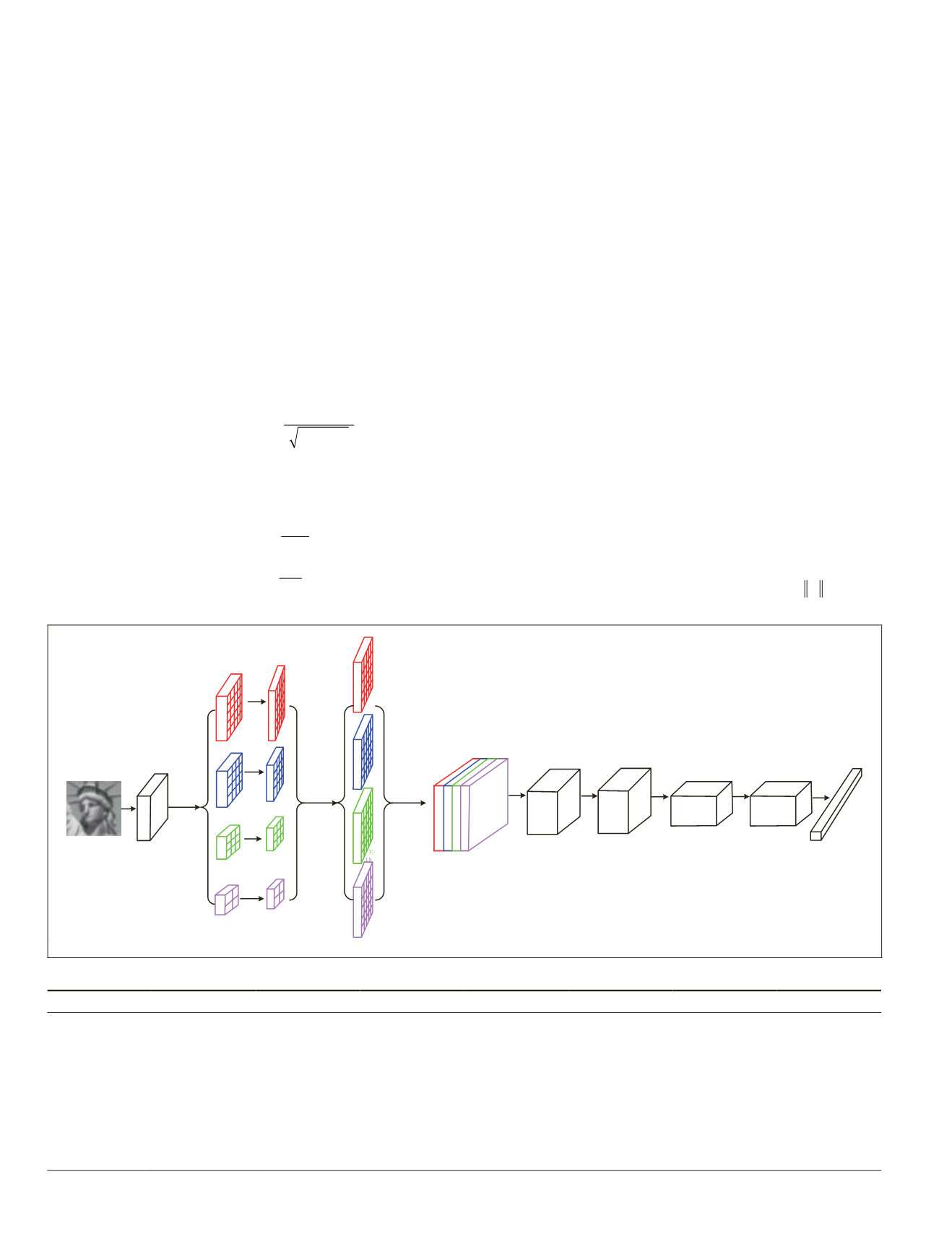
For better incorporating the global context of the image
patch, the pyramid convolutional network shown in Figure 2
is designed to extract the descriptor. More specifically, after
the first convolutional layer, the feature map
F
1
is rescaled
into four different resolution feature maps (
F
1
1
,
F
2
1
,
F
3
1
,
F
4
1
) us-
ing average pooling (LeCun
et al.
1998). Then the four feature
maps (
F
1
1
,
F
2
1
,
F
3
1
,
F
4
1
) are fed into four different networks to
obtain four different resolution feature maps (
F
1
2
,
F
2
2
,
F
3
2
,
F
4
2
).
The unified feature map
F
2
is obtained via concatenating the
four same resolution feature maps using
F
2
= (
F
′
1
2
,
F
′
2
2
,
F
′
3
2
,
F
′
4
2
)
(9)
where (
F
′
1
2
,
F
′
2
2
,
F
′
3
2
,
F
′
4
2
) are acquired via up-sampling the four
different resolution feature maps (
F
1
2
,
F
2
2
,
F
3
2
,
F
4
2
). Detailed
information about the network hyperparameters, including
stride and padding activation parameters, is shown in Table
layers obtained through average
ampled through bilinear interpola-
yer 2. The dropout rule provided
is used after layer 5 to prevent the
neural network from overfitting. Activation function
ReLU
is
used after every layer except the last layer.
Loss Function
In order to avoid setting the margin parameter, which has an
effect on the final performance in the triplet loss, we propose
a new distance loss function as follows:
(
)
d d
−
–
(
)
L
e
d d
i
N
a
i
p
i
a
i
n
i
=
+
+
–
=
∑
log
dist
dist
1
1
2
2
λ Θ
(10)
32
32
32
32
32
pooling
upsample
16
64
16
8
8
32
16
+
16
+
16
+
16
=64
32
128
32
4
4
32
8
8
16
32
16
32
32
32
32
16
32
16
16
16
16
8
8
16
4
4
32
16
32
32
16
32
2
16
32
32
32
concatenate
16
64
16
128
128
8
8
Figure 2. The architecture of the proposed pyramid
CNN
for learning the descriptor of an image patch.
Table 1. The detail parameters of the proposed network.
Layer
Input Size
Kernel Size
Stride
Padding
BatchNorm Activation
Output Size
1
1×32×32
3
1
1
32
ReLU
32×32×32
Scale1
32×32×32
1
1
0
16
ReLU
16×32×32
Scale2
32×16×16
1
1
0
16
ReLU
16×32×32
Scale3
32×8×8
1
1
0
16
ReLU
16×32×32
Scale4
32×4×4
1
1
0
16
ReLU
16×32×32
2
64×32×32
3
2
1
64
ReLU
64×16×16
3
64×16×16
3
1
1
64
ReLU
64×16×16
4
64×16×16
3
2
1
64
ReLU
128×8×8
5
128×8×8
3
1
1
128
ReLU
128×8×8
6
128×8×8
8
1
0
128
—
128×1×1
676
September 2019
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING


