TFeat (Balntas
et al.
2016) is a shallow
CNN
using triplets to
learn the local feature descriptor, and it shows that the ratio-
loss–based methods are more suitable for patch pair classi-
fication and that margin-loss–based methods work better in
nearest neighbor matching applications. The DeepCD network
structure learns a floating descriptor and a complementary
binary descriptor simultaneously by designing a data-depen-
dent modulation layer and optimizing the joint loss function
(Yang
et al.
2017). Tian
et al.
(2017) propose a different patch
descriptor learning architecture and use several strategies,
including a progressive sampling, the concept of the relative
minimal distance of matching pairs, information supervision
from the intermediate layers, and compactness of the learned
descriptor in the training phase. Mishchuk
et al.
(2017)
propose a novel loss that maximizes the distance between
the positive and the closest negative sample in a batch, and
it demonstrates that it has the state-of-art performance when
adopting the same network structure as in L2-Net.
Following the second line of stra
learn robust and discriminative des
by adopting a triplet
CNN
structure
loss function that can replace the d
handcrafted features, such as
SIFT
.
Proposed Method
Given a set of
N
training samples
I
= (
I
1
, …,
I
N
,
I
i
∈
R
m
×
m
) with a
spatial resolution of pixels, the proposed approach generates
a discriminative descriptor
d
i
(
d
i
∈
R
n
) for each image patch
I
i
using a pyramid triplet
CNN
.
Sampling Strategy
Sampling is important for training a neural network because a
lot of negative samples do not contribute to the optimization
and bias the learning step. Hence, many researchers focus
on hard mining techniques (i.e., selecting the proper nega-
tive samples). Our sampling strategy is the same as HardNet
(Mishchuk
et al.
2017), which selects the most challenging
negative image patches for every anchor image patch. The
descriptor
d
i
of every image patch
I
i
is obtained through the
network.
L
2
normalization is applied to every descriptor
d
i
:
|
d
i
| = 1,
"
i
. Thus, the distances between the two descrip-
tors
d
i
and
d
j
is computed via
dist
i j
d d
i j
,
( )
= -
2 2
(4)
Suppose there are
N
matching pairs {(
d
1
a
,
d
1
p
), …, (
d
N
a
,
d
N
p
)}
in a batch. Then the distance matrix
D
for the batch can be
obtained by
D
d d
d d
d d
d d
a p
a p
i
a p
N
a p
=
dist(
)
dist(
)
dist(
)
dist(
)
d
1 1
1
1
2 1
,
,
,
,
ist(
)
dist(
)
dist(
)
dist(
d d
d d
d d
d d
a p
i
a p
N
a
N
p
a
N
p
i
2
2
1
,
,
,
,
)
dist(
)
d d
a
N
p
N
,
(5)
gonal of the matrix represent the
r the corresponding matching pairs
hor patch
l
i
a
, the closest nega-
mallest element in the
i
-th row of
is,
j
*= arg min
j
dist(
d
i
a
,
d
j
p
),
j
∈
[1,
N
],
j
≠
i
. Similarly, the closest nonmatching image patch
I
a
k*
for the image patch
I
i
p
should be the smallest number among
the
j
-th column of the distance matrix
D
, that is,
k
*= arg min
k
dist(
d
k
a
,
d
i
p
),
k
∈
[1,
N
],
k
≠
i
. Thus, a triplet sample is defined via
Equation 6:
triplet
(
)
(
)
(
)
(
I I I
dist d d dist d d
I I
a
i
p
i
p
j
a
i
p
j
a
k
p
i
a
i
, ,
,
, ,
,
*
*
*
≤
p
i
a
k
a
i
p
j
a
k
p
i
I
dist d d dist d d
,
,
, ,
*
*
*
( )
)
(
)
(
)
>
(6)
In this way, the triplet sample, including the matching pair
(
l
i
a
,
l
i
p
) and the hardest sample whose descriptor is the closest
to one patch of the matching pair, is used to train the pro-
posed network.
Network Architecture
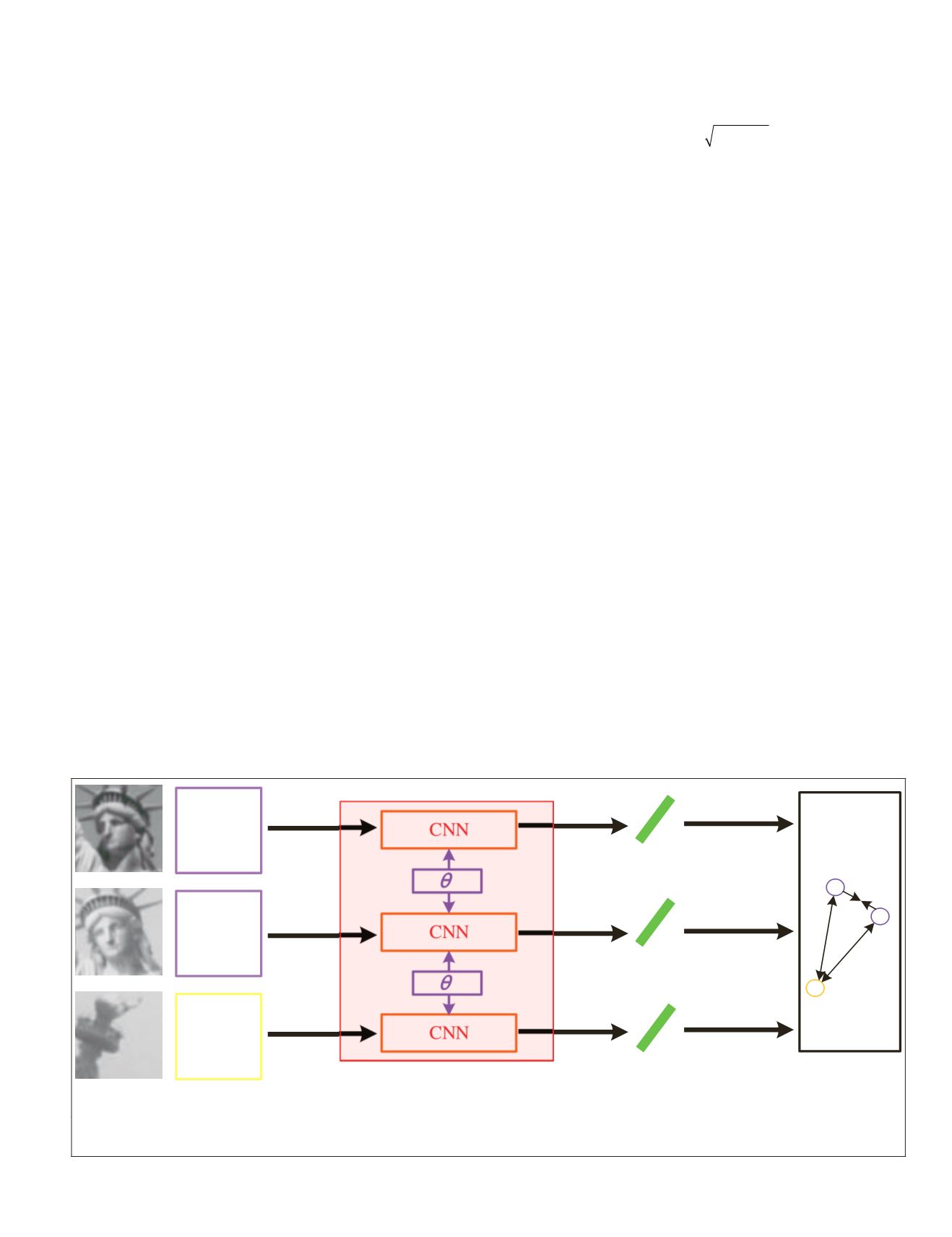
The schematic of the triplet network is depicted in Figure
1. The corresponding descriptors (
d
a
,
d
p
,
d
n
) for the anchor,
Anchor
Patch
CNN
CNN
CNN
a
p
n
Loss
Positive
Patch
Negative
Patch
Triplet Network: share weights
Descriptor
Descriptor
Descriptor
Figure 1. Schematic of the triplet network, where three image patches are processed by the same
CNN
. The details of the
CNN
structure is shown in Figure 2.
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING
September 2019
675


