Several open source implementations of random forest
classification are available. In this study, we implemented
random forest classification by using a popular machine learn-
ing algorithm software called Weka 3.6.10(Hall
et al
., 2009),
which is a stable version software package written in Java
available under the
GNU
General Public License. Small issues
relating to the out-of-bag accuracy have been revised very
recently, and a newer version, namely, Weka 3.7 Developer, is
now available. In addition, we have extended the algorithm to
output the out-of-bag error, kappa coefficient, and conditional
kappa coefficient for random forest models with 1 to 150 ran-
dom trees for a fixed feature number and random seed.
Evaluations of Classifier’s Accuracy and Thematic Map Accuracy
The classifier’s accuracy and the thematic map accuracy were
evaluated in order to examine how algorithmic parameter
settings could affect the performance of random forests in clas-
sifying prototype data as well as unknown pixels, respectively.
The former (or classifier’s generalization error) was quantified
during the training phase, using the out-of-bag (
OOB
) error
estimate which equals to the incorrectly classified instances
divided by the entire out-of-bag samples (Wolpert and Mac-
ready, 1999).The
OOB
error was calculated for each of 13 land
cover subcategories before combining them into ten major
categories.
The thematic map accuracy was quantified through the er-
ror matrix analysis (Congalton, 1991). While the
OOB
error es-
timate is used to quantify the performance of random forests
with prototype data, the error matrix analysis with reference
samples takes the true class proportions on the ground into
consideration, and therefore is considered as a reliable indi-
cator of the accuracy (Congalton, 1991; Richard, 1996). For
thematic map accuracy assessment, a reference dataset was
prepared using a stratified random sampling strategy, with the
class identity determined through combining the information
derived from field observations and the ancillary data. A total
of 600 sample points were included in the reference dataset
with an average of 60 for each major land cover category (see
Table 1). This reference dataset was used in the accuracy as-
sessment for each classified map. Note that various discrete
multivariate techniques such as Kappa analysis (Congalton,
1991) and quantity disagreement and allocation (Pontius and
Millones, 2011) can be used to quantify the thematic map
accuracy. Because of the robustness and popularity, Kappa
statistics were used here, which are excellent in analyzing
a single error matrix or compare various matrices (Congal-
ton, 1991). Overall Kappa statistics and conditional Kappa
statistics were computed for each map. Further synthesis and
analysis will focus on the interpretation of the overall kappa
and conditional kappa coefficients in relation to specific ran-
dom forest models with varying parameter settings.
In addition to the descriptive analysis, we have conducted
the Z-test to examine if there is a significant difference be-
tween the classification accuracies by random forest models
with changing parameters (e.g., Congalton and Green, 2009).
If the Z-statistic for the kappa coefficients produced using
two different parameter settings is larger than 1.96, then it
strongly suggests that changing parameters lead to significant-
ly different classification accuracies by random forest models
(95 percent confidence).
Results and Discussion
The ultimate goal of this study was to assess how algorithmic
parameters could affect the performance of random forests
in image classification. The two algorithmic parameters, i.e.,
the number of trees and the number of features, were targeted
here; although another internal parameter, the random seed
number, was also included in the discussion. We compared
the out-of-bag error estimate and the Kappa coefficient from
different models configured with specific settings as the
basis to evaluate the sensitivity of random forests to internal
parameter settings. As mentioned before, these models were
constructed with one parameter altered at one time while
holding the others unchanged.
Tree Number and Classification Accuracy
The impact of the tree number on the performance of random
forests was examined here. As mentioned earlier, the tree
number ranging from 1 to 150 was considered in this study.
First, the sensitivity of random forests to changing tree num-
bers was assessed using the out-of-bag (
OOB
) error estimate.
Note that this metric for each random tree number tested was
averaged for the feature number ranging from 1 to 7 with 10
random seeds so that the comparison can target the algorith-
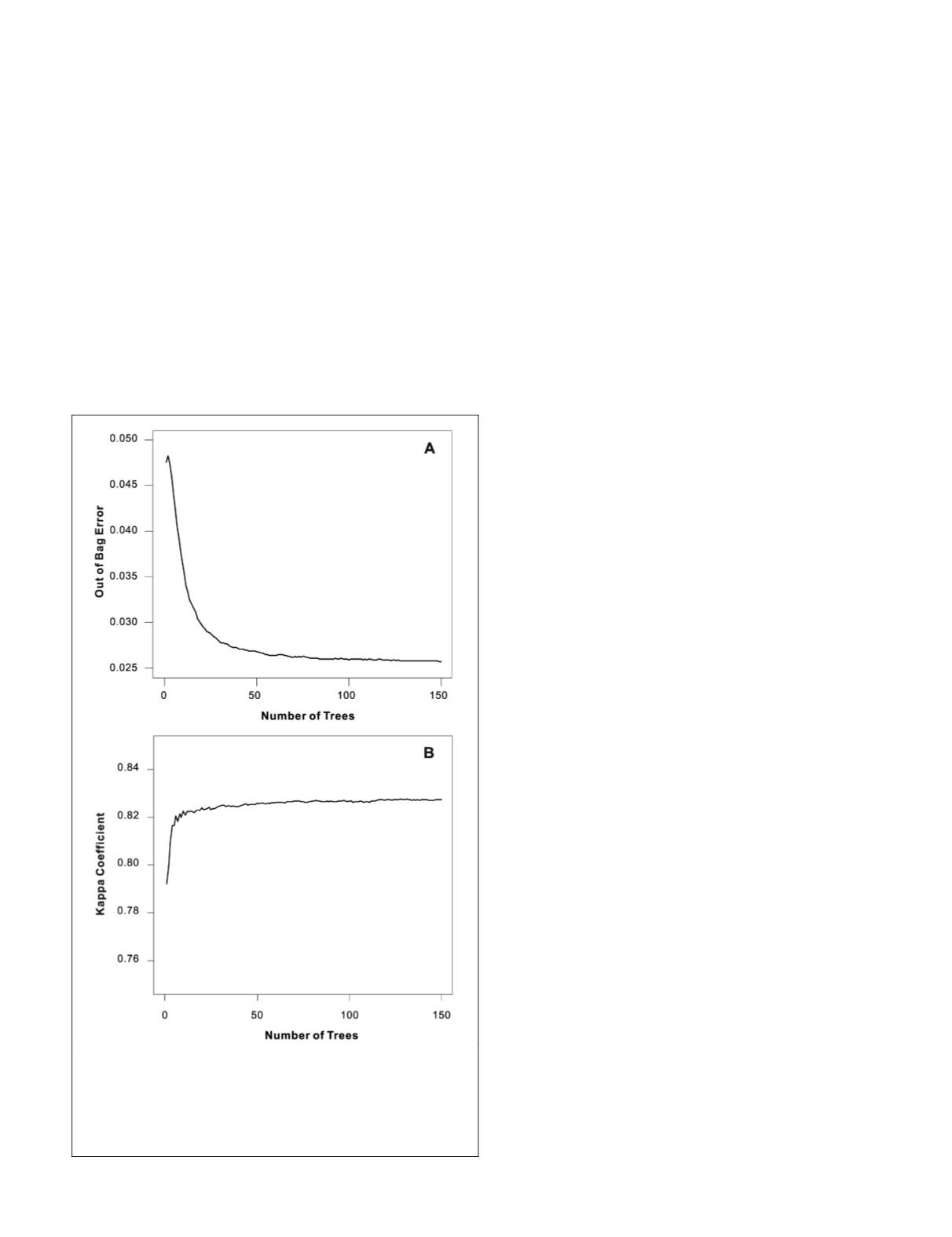
mic parameter itself (i.e., the tree number). Figure 2A illus-
trates the trend of the
OOB
error in relation to the tree number
tested. Overall, the
OOB
error declined (i.e., the classifier’s
accuracy increased) as more trees were used. The
OOB
error
was the highest (i.e., 0.048) when only one tree was used.
Figure 2. Classifier’s accuracy and thematic map accuracy in
relation to the tree number: (A) Classifier’s accuracy measured by
the out-of-bag error for each tree number that was averaged for
the feature number from one to seven with ten different random
seeds, and (B) Map accuracy quantified with the Kappa coef-
ficient for each tree number that was averaged for the feature
number from one to seven with ten different random seeds.
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING
June 2016
411


