is time consuming and especially
inefficient in an online model.
GP
models have been applied
for human motion analysis and
activities recognition
[4]
,
[13]
because
of its robustness and high accu-
racy in classification. However,
GP
models are supervised. They must
be fed with manually labeled data
set. On the other hand,
GP
models
require proper features to model
events such as the most widely
used trajectories
[14]
,
[15]
. However,
tracking-based methods depend
crucially on the performance of
detection and tracking which is
costly or even impossible in our
complex and crowded scene. Li
et
al.
[12]
proposed to detect anoma-
lies in crowds utilizing Gaussian
process regression models, which
adopts HOF features to describe
motion patterns. But their work is
unable to analyze individual activ-
ity and interaction occurring in
the surveillance scene. Hu
et al.
[16]
combined the
HDP
model with One-
Class SVM by using Fisher kernel.
Tang
et al.
[17]
proposed an alterna-
tive method to combine features for
complex event recognition. How-
ever, this method is unfeasible in a
surveillance video because of the
low-quality video and too many objects. The low-level visual
features are much more applicable in this scene.
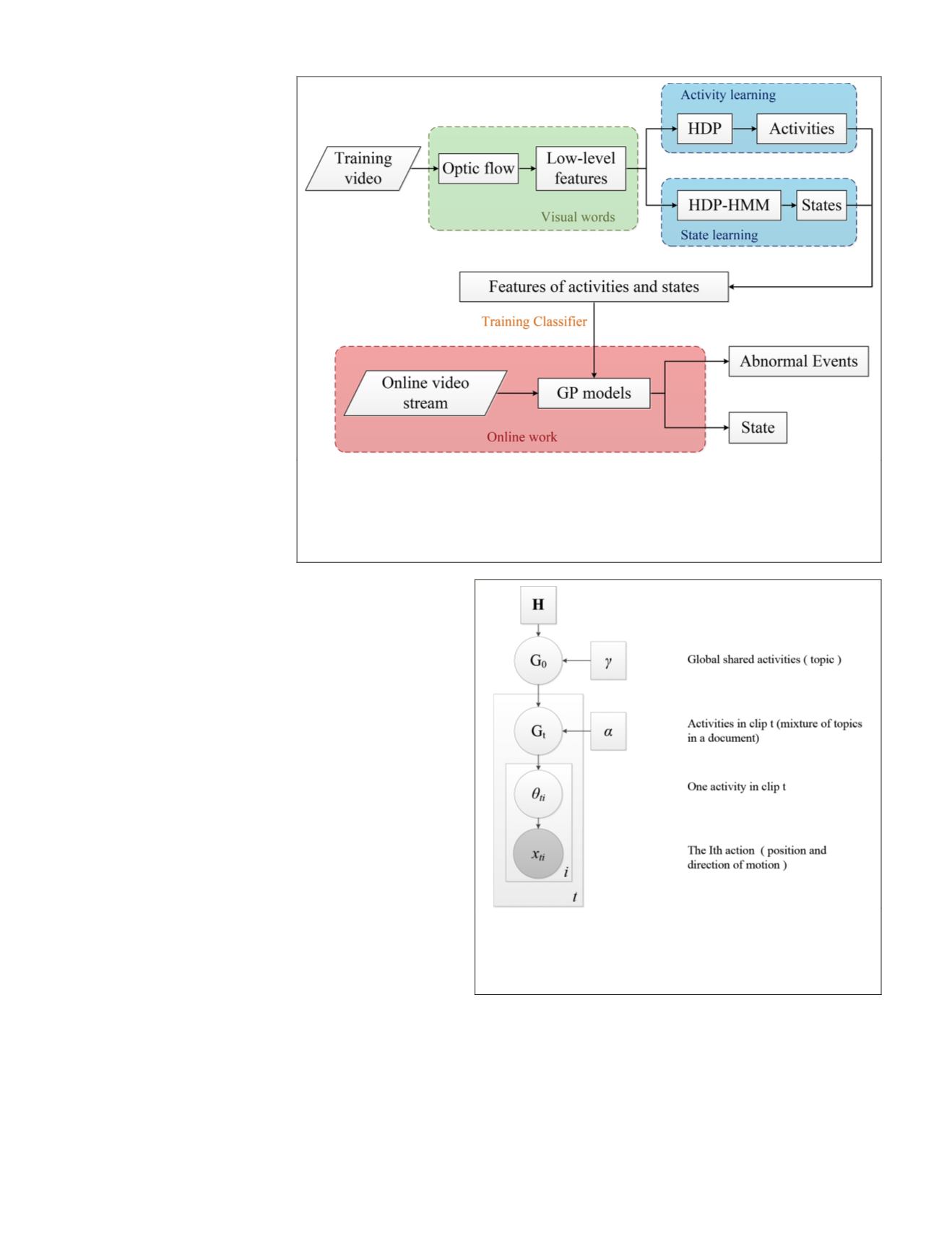
Figure 1 is an overview of our proposed framework. It’s
roughly divided into three parts. In the first part (in the green
block), visual words are generated based on location in the
image plane and direction to represent quantized motion in-
formation. Then, the
HDP
models learn the activity patterns in
an unsupervised way (in the blue block). Finally, the learned
patterns are used to train the
GP
models (in the red block) for
our final goal of this work: activity recognition and anomaly
detection.
Visual Features Representation
Our datasets are surveillance videos from complex and
crowded traffic scenes and captured by a fixed camera. They
contain a large quantity of activities and interactions. Many
unavoidable problems such as occlusions, a variety object
types, small size of objects challenge detection and tracking
based methods. In such case, using the local motions as low-
level features is a reliable way. First, the optical flow vec-
tor for each pixel between each pair of successive frames is
computed using
[18]
. A proper threshold is necessary to reduce
noise: the intensity of a flow is greater than the threshold is
deemed as reliable. Similar to
[13], [10], [19]
. We spatially divide
the camera scene into non-overlapping square cells of size 8
× 8 pixels to get rough position features. We average all the
optical flow vectors in the cell and quantize it into one of the
8 directions (Figure 2) as a local motion feature. A low-level
feature is defined as the position of the cell (
x
,
y
) and its mo-
tion direction. The image size of the two
QMUL
datasets
[19]
is
360*288, thus they have 12,960 words, while the MIT dataset
[9]
(480*720) has 43,200 words. Each word is represented
by an unique integer index. The input videos are uniformly
segmented into non-overlapping clips for 75 frames each (3
seconds) and each video clip is viewed as a document which
is a bag of all visual words
w
t
occurring in the clip. The
whole input video is a corpus.
Model
Our first task is to infer the typical activities and traffic states
from given video. The low-level features are the exclusive
motion information that can be directly observed from the
input video. An activity is a mixture of local motions that
frequently co-exist in the same clips (or documents). Thus,
Figure 1. An overview of our proposed framework. It’s roughly divided into three parts.
In the first part (the green block), visual words are generated based on location in the
image plane and direction to represent quantized motion information. Then, the
HDP
models learn the activity patterns in an unsupervised way (in the blue block). Finally,
the learned patterns are used to train the
GP
models (in the red block) for our final goal
of this work: activity recognition and anomaly detection.
Figure 2. A graphical representation of
HDP
model. It
consists of two Dirichlet Processes. The first one is used to
generate a global set of activities and the second one is used
to sample a subset of activities from the global set for a clip.
Finally, visual words are drawn from activities.
204
April 2018
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING


