Evaluation Outputs
The quality assessment methods
can produce two kinds of outputs:
geometric fidelity metrics and
labels of errors.
Geometric fidelity metrics sum-
marize the quality at the building
level. These criteria are computed
at different levels: average preci-
sion of specific points of interest
(corners or edge points, (Vögtle and
Steinle 2003; Kaartinen
et al.
2005),
surface dissimilarity (Jaynes
et al.
2003; Dick
et al.
2004; Kaartinen
et
al.
2005; Zebedin
et al.
2008; Lafarge
and Mallet 2012; Zeng
et al.
2014; Li
et al.
2016; Nan and Wonka 2017),
average mean absolute distance
(Duan and Lafarge 2016; Zeng
et
al.
2018), tensor analysis of residu-
als (You and Lin 2011) or volume
discrepancy to reference data
(Jaynes
et al.
2003; Zeng
et al.
2014;
Nguatem and Mayer 2017). Evalua-
tion can also be performed according to compactness, which is
complementary to fidelity metrics: number of faces/vertices in
the model (Lafarge and Mallet 2012; Zhang and Zhang 2018).
For both cases, the obtained outputs have the drawback of being
too general for the special case of urban structured models. Far
from surface reconstruction evaluation (Berger
et al.
2013), it is
preferred that a diagnosis pinpoints specific types of errors that
can be easily corrected with specific procedures (Elberink and
Vosselman 2011).
Semantic errors identify topological and geometric errors
that affect building models. One example of such defects is the
traffic light paradigm (“correct,” “acceptable/generalized,” and
“incorrect”) (Boudet
et al.
2006). However, these errors depend
on the definition of the end-user oriented nomenclature and a
specific “generalization” level at which models are rejected. In
addition, this taxonomy does not help in localizing the model
shortcomings. Another solution is to look at the issue at hand
through the used reconstruction algorith
instance, defects are discriminated in Mi
between footprint errors (“erroneous out
building,” “missing inner court,” and “i
intrinsic reconstruction errors (“over-segmentation,” “un-
der segmentation,” “inexact roof,” and “Z translation”), and
“vegetation occlusion” errors or are considered only for roof
topology as in (Xiong
et al.
2014) (“Missing Node,” “False
Node,” “Missing Edge,” and “False Edge”). In most of these
methods, the evaluation is cast as a supervised classification
process: the predicted classes are defects listed in an estab-
lished taxonomy. Features used for this classification are ex-
tracted from very high spatial resolution (
VHR
, 0.1 m to 0.5 m)
images and
DSMs
, like 3D segments or texture correlation score
comparisons. In spite of their semantic contribution in quality
evaluation, such taxonomies are prone to overfitting to specific
urban scenes/modeling algorithms or require the computation
of complex features on
VHR
data that do not scale well.
Problem Statement
This work aims to propose a new quality evaluation para-
digm that detects and describes semantic errors that affect
3D building models. Two important characteristics must be
taken into account. First, the definition of the semantic errors
should not vary from one urban scene to another and guaran-
ty independence to the underlying 3D reconstruction method.
Second, the scalability of the method should be addressed in
order to ensure the ability to correctly classify unseen areas
and to define the minimal amount of data required. This is all
the more necessary in case of limited training sets in order to
avoid overfitting to a specific problem and environment.
Problem Formulation
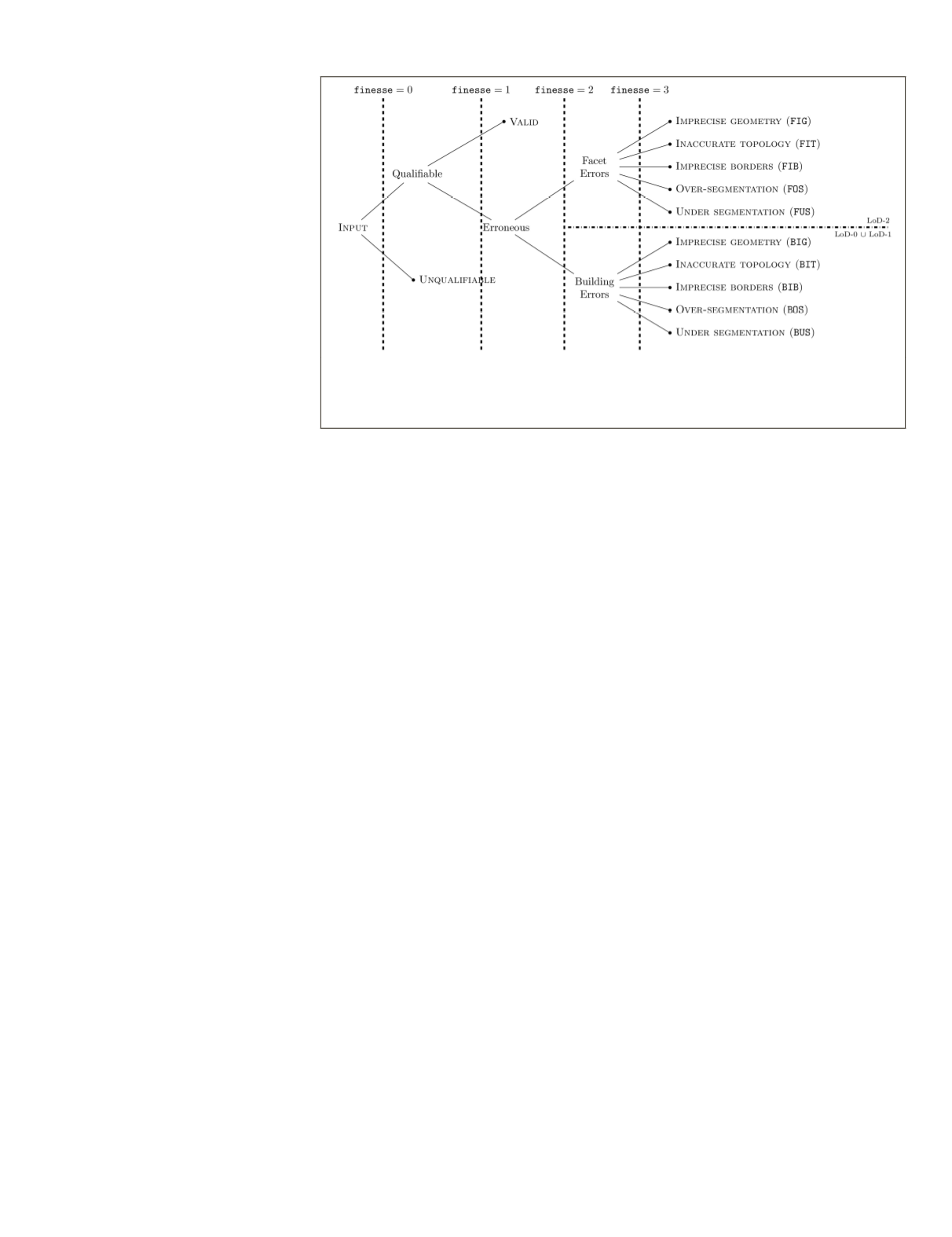
We start by establishing a novel hierarchical error taxonomy.
It is parameterizable and agnostic towards reconstructed
models.
1
Independence from the modeling method and the
urban scenes is mandatory for generalization and transfer-
ability capacities. Depending on the evaluation objectives,
we deduce error labels that can pinpoint defects altering the
models. Their presence is predicted using a supervised classi-
fier, trained with manually annotated data.
The quality assessment pipeline is constructed in order
to be modular. Building models are represented by intrinsic
geometric features extracted from the model facet graph. If
available, the classifier can also be fed with remote sensing
ased on the comparison of the model
r image information with spectral or
able in satellite, aerial or street view
Error Taxonomy
In order to build a generic and flexible taxonomy, we rely on
two criteria for error compilation: the building model
LoD
and
the error semantic level, named henceforth
finesse
(cf. Figure
2). Different degrees of finesse describe, from coarse to fine, the
specificity of defects. Errors with maximal finesse are called
atomic
errors. Multiple atomic errors can affect the same build-
ing. For instance, topological defects induce, almost always, geo-
metrical ones. In practice, only independently coexisting atomic
defects are reported. The idea is to provide the most relevant
information to be able to correct a model. Atomic errors can thus
be intuitively correlated to independent actions, to be chosen by
an operator or an algorithm, so as to correct the model.
The General Framework
The main idea of error hierarchization is to enable modularity
in the taxonomy, and thus achieve a strong flexibility towards
input urban scenes and desired error precision. A general layout
is first drawn, followed by a more detailed error description.
At a first level, model qualifiability is studied. In fact, aside
from formatting issues or geometric inconsistencies (Ledoux
2018), other reasons make building models unqualifiable.
For instance, buildings can be occluded by vegetation and
Figure 2. The proposed taxonomy structure. In our case of Very High Resolution
overhead image modeling, only two family errors are depicted. At finesse level 2,
hierarchization is possible: the exclusivity parameter can thus act. However, it is not
the case at the atomic errors level since they are independent.
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING
December 2019
867


