Improved Depth Estimation for Occlusion Scenes
Using a Light-Field Camera
Changkun Yang, Zhaoqin Liu, Kaichang Di, Changqing Hu, Yexin Wang, and Wuyang Liang
Abstract
With the development of light-field imaging technology,
depth estimation using light-field cameras has become a
hot topic in recent years. Even through many algorithms
have achieved good performance for depth estimation using
light-field cameras, removing the influence of occlusion,
especially multi-occlusion, is still a challenging task. The
photo-consistency assumption does not hold in the presence
of occlusions, which makes most depth estimation of light-
field imaging unreliable. In this article, a novel method to
handle complex occlusion in depth estimation of light-field
imaging is proposed. The method can effectively identify
occluded pixels using a refocusing algorithm, accurately
select unoccluded views using the adaptive unoccluded-view
identification algorithm, and then improve the depth estima-
tion by computing the cost volumes in the unoccluded views.
Experimental results demonstrate the advantages of our
proposed algorithm compared with conventional state-of-the
art algorithms on both synthetic and real light-field data sets.
Introduction
Light fields (Levoy and Hanrahan 1996) capture not only the
radiance but the angular direction of each ray from a scene.
Therefore, they can depict the 3D structure of the scene. As a
device to acquire a light field, light-field cameras from compa-
nies such as Lytro (Ng
et al.
2005) and Raytrix (
.
de) have drawn wide attention in computational photography,
computer vision, and close-range photogrammetry. Compared
with traditional cameras, light-field cameras place a microlens
array between the main lens and the charge-coupled device
array, as shown in Figure 1. Thanks to this microlens array,
the light-field camera is capable of capturing multiple views
of the scene in a single snapshot, enabling passive depth
estimation, which has wide potential applications including
autonomous vehicles (Menze and Geiger 2015), light-field
segmentation (Mihara
et al.
2016), 3D reconstruction (Kim
et
al.
2013), and simultaneous localization and mapping (Dong
et al.
2013).
Depth estimation from light-field cameras is based on
a common assumption that when refocused to the correct
depth of one spatial pixel in the center subaperture image, all
viewpoints (angular pixels) converge to the same point in the
scene (Figure 2). If we collect the angular pixels to form an
angular patch, they exhibit photo-consistency for Lambertian
surfaces, which means their colors ought to be the same or
similar. In setting a different refocusing depth, the depth
corresponding to the minimum variance of the angular patch
is the correct one. Many algorithms have been proposed for
depth estimation from light-field cameras under this assump-
tion. Perwaß and Wietzke (2012) proposed an algorithm to
estimate depth from light-field cameras using correspondence
techniques. Wanner and Goldluecke (2013) proposed a local
Changkun Yang is with the State Key Laboratory of Remote
Sensing Science, Aerospace Information Research Institute,
Chinese Academy of Sciences, Beijing, China; and the Beijing
Institute of Aerospace Control Devices, Beijing, China.
Zhaoqin Liu, Kaichang Di, Yexin Wang, and Wuyang Liang
are with the State Key Laboratory of Remote Sensing Science,
Aerospace Information Research Institute, Chinese Academy
of Sciences, Beijing, China (
).
Changqing Hu is with the Beijing Institute of Aerospace Control
Devices, Beijing, China; and the Pilot National Laboratory for
Marine Science and Technology, Qingdao, China.
Photogrammetric Engineering & Remote Sensing
Vol. 86, No. 7, July 2020, pp. 443–456.
0099-1112/20/443–456
© 2020 American Society for Photogrammetry
and Remote Sensing
doi: 10.14358/PERS.86.7.443
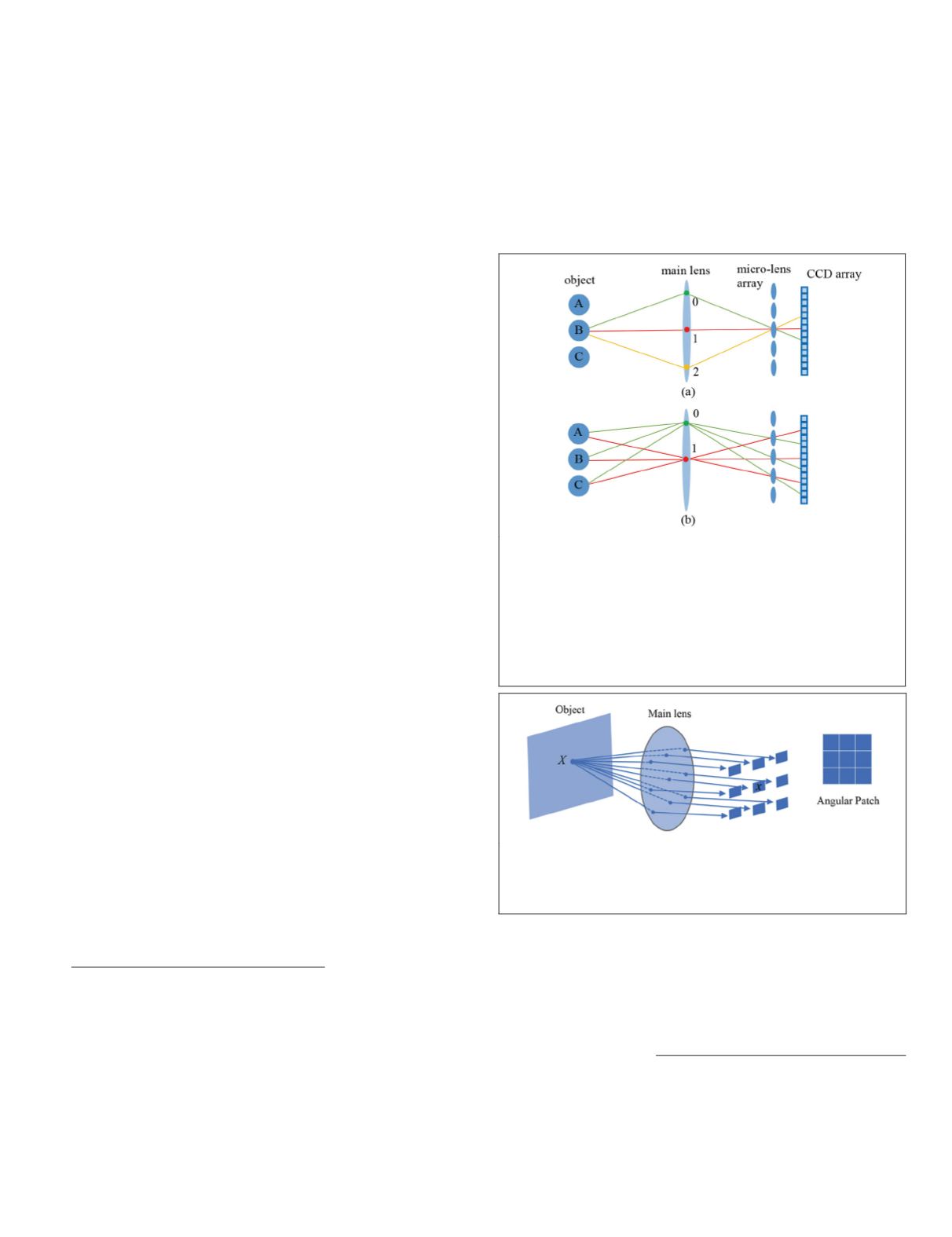
Figure 1. Imaging model of a lenslet light-field camera. (a)
The different direction rays (red, green, and yellow lines)
from object
B
are recorded in different pixels in the charge-
coupled device array. 0, 1, and 2 represent different locations
on the main lens. Location 1 is the center of the main lens. (b)
The rays passing through the same location on the main lens
are collected to form subaperture images. The subaperture
image formed by the rays passing through location 1 on the
main lens is called the center subaperture image.
Figure 2. Refocusing model of the light field. For an
unoccluded pixel
x
in the center-view image, all view rays
converge to the corresponding object point
X
in the scene if
refocused to the correct depth.
PHOTOGRAMMETRIC ENGINEERING & REMOTE SENSING
July 2020
443


